
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 한번에끝내는Java/Spring웹개발마스터초격차패키지
- 알버트
- AI
- 패캠챌린지
- R
- 한번에 끝내는 Java/Spring 웹 개발 마스터 초격차 패키지 Online
- SKT
- 직장인인강
- 직장인자기계발
- 한번에 끝내는 Java/Spring 웹 개발 마스터 초격차 패키지
- 패스트캠퍼스
- albert
- 패스트캠퍼스후기
- 한번에 끝내는 Java/Spring 웹 개발 마스터 초격차 패키지 Online.
- Today
- Total
제주 탈출 일지
빅데이터 분석 - 선형 그래프 그리기 본문
이번 포스팅에서는 R을 통해 선형그래프를 그리는 것을 정리해보도록 하겠다. 이 포스팅을 따라하면 아래와 같은 예쁜 그림을 얻을 수 있다. 시작하겠다.
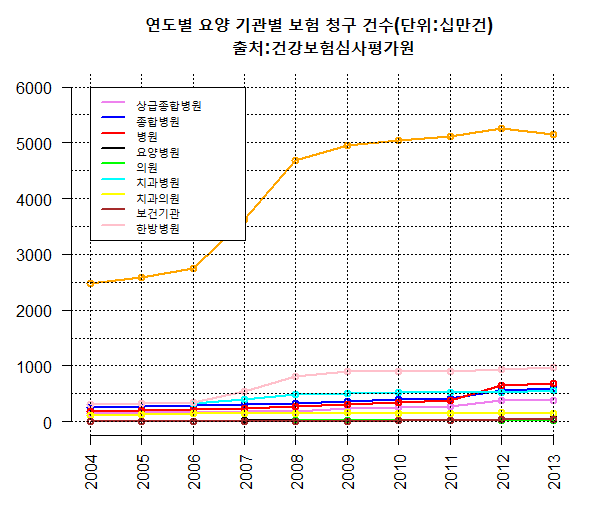
먼저 선형 그래프는 이와같이 여러가지 항목의 연도별 변화를 관찰하는데 용이하다. 결국 자신이 분석할 데이터에 가장 잘 맞는다고 판단되는 그래프를 선정해야 하므로 예제를 생각하며 하는것을 권한다.
Step 1. 파일을 불러오고 형태를 확인한다.
count <- read.csv("연도별요양기관별보험청구건수_2001_2013_세로.csv", stringsAsFactors = FALSE)
count
colname <- count$년도
v1 <- count[,2]/100000
v2 <- count[,3]/100000
v3 <- count[,4]/100000
v4 <- count[,5]/100000
v5 <- count[,6]/100000
v6 <- count[,7]/100000
v7 <- count[,8]/100000
v8 <- count[,9]/100000
v9 <- count[,10]/100000
v10 <- count[,11]/100000
v1
다음은 데이터를 read.csv를 통해 불러왔을 때, 확인한 형태이다.
년도 상급종합병원 종합병원 병원 요양병원 의원 치과병원 치과의원 보건기관 한방병원 한의원
1 2004 15583978 25177454 18242052 308855 247545398 831809 31550525 11998632 1167354 30359202
2 2005 15967303 26846886 19572867 556888 259203708 911653 32247062 12028815 1161308 32585757
3 2006 17014445 28466480 21402364 906495 274452725 1066661 32929058 14628337 1045650 35081895
4 2007 18001309 30480172 24113643 1515366 362304188 1235259 40495113 14598704 1078144 54945811
5 2008 19084837 33390693 26601460 1964108 468198761 1371121 49529829 14630679 1057888 80278823
6 2009 23521523 35544045 30732776 2447613 495396105 1572912 51022765 16000157 1191822 89161158
7 2010 26088048 39074514 34437415 2666027 504417806 1805304 51835860 15232748 1296015 90060199
8 2011 26960401 40803979 37347054 2978828 510867833 2001164 52151423 14578392 1467392 90542681
9 2012 37478189 55860792 64356977 4817074 524890875 2751766 52957117 15841288 3282584 93096375
10 2013 38877052 58851945 68077999 5232408 515038775 2955361 55593617 14537614 3421751 97704335
굉장히 큰 숫자들을 볼 수가 있다. 십만 ~ 억단위의 숫자들을 처리하기에는 한눈에 보기가 어려우므로 십만단위로 나누어준다. 나누는 과정에서 count[,숫자] 형태로 나누어 vN 벡터에 넣어주게 되는데, 한 열의 자료끼리 묶어서 나누기 위함이다. 궁금하다면 count[1,1], count [2,1] ... 들의 값의 변화가 어떻게 일어나는 지 확인해보면 바로 이해할 수 있다.
colname$변수(변수라고 표현하는 것이 맞는지 모르곘다.)를 하게 되면 해당 속성의 값들이 추출되게 된다. colname$년도는 2004년부터 2013년까지의 값이 하나의 벡터로 추출된다.
v1을 확인해보면 다음과 같은 데이터가 나오게 된다.
> v1
[1] 155.8398 159.6730 170.1445 180.0131 190.8484 235.2152 260.8805 269.6040 374.7819 388.7705Step 2. plot을 그린다.
plot(v1,xlab="",ylab="",ylim=c(0,6000),axes=FALSE,col="violet",type="o",lwd=2,
main=paste("연도별 요양 기관별 보험 청구 건수(단위:십만건)","\n","출처:건강보험심사평가원"))
axis(1,at= 1:10,label=colname, las=2)
axis(2, las=1) 이전 barplot을 잘 공부했다면 크게 다른 것은 없다. 다만, type="o" 를 통해 선그래프를 그릴 것인데, 이 인자는 선과 점을 동시에 표현하여 그래프를 그려준다. 그러면 v1의 인자의 값을 하나하나 점으로 찍고, 점과 점을 선으로 이어주는 그래프가 하나 나오게 된다.

이제 축을 그려야 하는데, 사실 plot 함수에서도 axes=TRUE로 한다면 축을 그릴 수 있다. 편의사항이지만, 나는 축을 따로 그려주는 것이 훨씬 예쁘게 그릴 수 있다고 느껴진다. 또한, 하나의 plot 함수에 너무 많은 인자가 들어가서 보기 어려워지므로 axis함수를 통해 그냥 따로 그리는 것을 추천한다.
axis함수의 첫번째 인자 1은 x축을 나타낸다. 2는 당연히 y축이다. (3은 천장 x축, 4는 오른쪽 y축이다.)
우리는 x축에 연도를 표시하려한다. 2004년부터 2013년까지 10개의 레이블이 필요하다. 그래서 at = 1:10으로 x축 값 10개를 표시하고, 그 후 colname$연도를 통해 생성해두었던 벡터를 레이블로 사용하여 표시를 해주게 된다. 또 y축의 레이블 스타일을 축의 수직방향으로 우리가 보기 편하도록 las=1을 통해 설정하게 된다.

Step 3. 나머지 항목들을 그린다.
이미 v1은 그렸으므로 그리지 않은 v2 ~ v10까지를 그려야 한다.
lines(v2, col="blue", type= "o", lwd =2)
lines(v3, col="red", type= "o", lwd =2)
lines(v4, col="black", type= "o", lwd =2)
lines(v5, col="orange", type= "o", lwd =2)
lines(v6, col="green", type= "o", lwd =2)
lines(v7, col="cyan", type= "o", lwd =2)
lines(v8, col="yellow", type= "o", lwd =2)
lines(v9, col="brown", type= "o", lwd =2)
lines(v10, col="pink", type= "o", lwd =2)
이제는 plot을 미리 그렸으므로 lines함수를 통해 plot 위에 덧씌울 것이다. 인자도 이전 plot과 크게 다르지 않다.

Step 4. 격자와 범례를 그린다.
선 그래프의 항목들을 쉽게 파악하기 위해 격자와 범례를 그려주면 좋다. 보는 사람이 편해질 것이다.
abline(h=seq(0,6000,500), v=seq(1,10,1), lty=3, lwd= 0.2)
col <- names(count[1, 2:10])
colors <- c("violet", "blue", "red", "black", "green", "cyan", "yellow", "brown", "pink")
legend(1, 6000, col, cex=0.8,col=colors, lty=1, lwd = 2, bg ="white")
먼저 격자를 그리는 것은 가로, 세로를 통해 그리게 된다. 인자를 보면 h, v가 있는데 각각 horizental, vertical의 약자이다. 즉, 선을 그리는 너비와 높이를 주고, 선의 형태를 어떤식으로 그릴것인지에 대한 인자를 주는 것이다. h=seq(0,6000,500), v=seq(1,100,1)했으므로 높이는 0부터 500씩 마다 그릴 것이고, 너비는 1부터 10까지 1씩마다 그릴것이다.(2004부터 2013이 아니다. 2004와 같은 값들은 실제 값이 아니라 C에서의 열거형과 같은 느낌이라고 생각하면 좋겠다.)
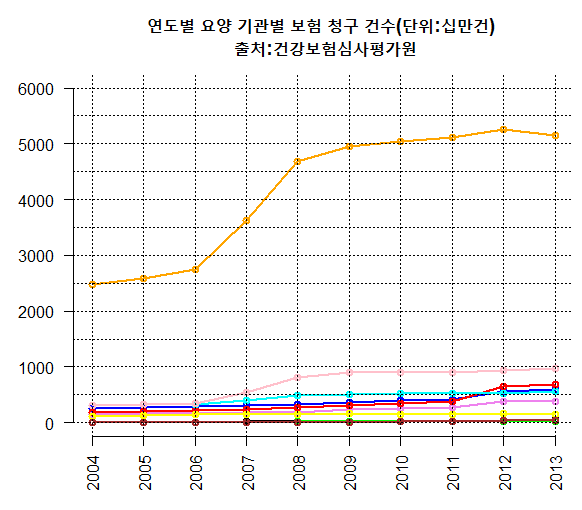
그 후 범례를 그리는데, 범례에서 우리가 사용한 색상에 맞게 대응되어야 한다. 그를 위해 우리가 필요한 요양 기관에 대한 이름과, 색상을 순서에 맞게 얻어야 한다.
col <- names(count[1, 2:10])
colors <- c("violet", "blue", "red", "black", "green", "cyan", "yellow", "brown", "pink") 이 코드에서 첫번쨰 col <- names()함수는 우리가 원하는 부서를 얻어주고, colors <- c()에서는 우리가 가내수공업으로 v1부터 사용한 순서대로 적어놓은 것을 볼 수가 있다. 처음부터 사용할 때 이런식으로 정해주고 사용하는 것이 더 편리할 것이다.(벡터의 []연산을 이용하여 반복문으로 차례차례 선을 그릴 수 있을 것이다.)
legend(1, 6000, col, cex=0.8,col=colors, lty=1, lwd = 2, bg ="white")legend 함수에서 사용된 인자는 (x 좌표, y 좌표, 사용할 데이터(요양 부서), 글자크기(cex), 선의 타입(대쉬), 선의 너비, 배경(하얀색)) 이런식으로 대응된다. 이제는 이러한 인자를 많이 접했기 떄문에 크게 어려움이 없으리라 생각된다.

이렇게 선 그래프를 R로 그리는 예제를 포스팅해보았다. 빅데이터 처리는 하나의 실무적인 과정으로 이해보다는 숙달하는 것이 중요하다고 판단된다. 까먹을 때마다 반복해서 몸으로 체득하는 것이 중요하겠다.^^
'빅데이터 분석' 카테고리의 다른 글
| 빅데이터 분석 - 네이버 실시간 검색어 & 코스피 지수 데이터 크롤링 (0) | 2020.10.02 |
|---|---|
| 빅데이터 분석 - R 웹크롤링 포스팅 정리 (0) | 2020.09.30 |
| 빅데이터 분석 - tm패키지를 사용하여 영어 비정형 데이터 분석 (0) | 2020.09.28 |
| 빅데이터 분석 - csv파일을 읽어 barplot 그래프 그리기 (0) | 2020.09.19 |
| 빅데이터 분석 - 비정형 데이터 처리(wordcloud2) (0) | 2020.09.08 |


